Inference Profiler
High-resolution, production-scale inference profiling across models, engines, and GPUs.
NVIDIA PyTorch
PyTorch Hugging Face
Hugging Face vLLM
vLLM SGLang
SGLang
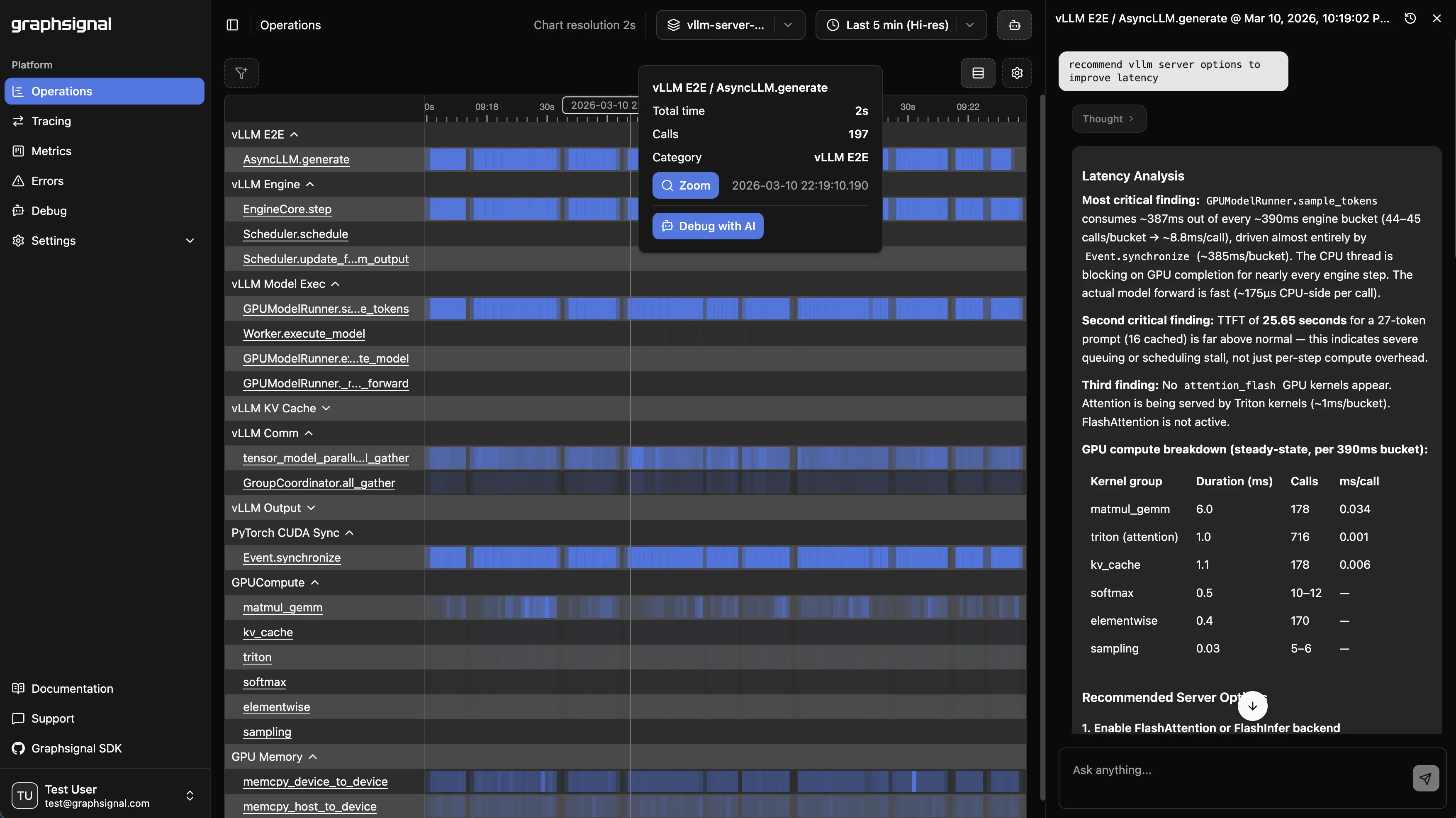
Inference profiling
Continuous, high-resolution profiling timelines exposing operation durations and resource utilization across inference workloads.
LLM tracing
LLM generation tracing with per-step timing, token throughput, and latency breakdowns for major inference frameworks.
System metrics
System-level metrics for inference engines and hardware (CPU, GPU, accelerators).
Error monitoring
Error monitoring for device-level failures, runtime exceptions, and inference errors.
AI optimization
Inference telemetry for AI agents to identify bottlenecks and drive targeted improvements across the inference stack.